Administration Guide
This section contains concepts and tasks to help you manage your Eucalyptus cloud.
This is the multi-page printable view of this section. Click here to print.
This section contains concepts and tasks to help you manage your Eucalyptus cloud.
The section shows you how to access Eucalyptus with a web-based console and with command line tools. This section also describes how to perform common management tasks. This document is intended to be a reference. You do not need to read it in order, unless you are following the directions for a particular task.
Eucalyptus is a Linux-based software architecture that implements scalable, efficiency-enhancing private and hybrid clouds within an enterprise’s existing IT infrastructure. Because Eucalyptus provides Infrastructure as a Service (IaaS), you can provision your own resources (hardware, storage, and network) through Eucalyptus on an as-needed basis.
A Eucalyptus cloud is deployed across your enterprise’s on-premise data center. As a result, your organization has a full control of the cloud infrastructure. You can implement and enforce various level of security. Sensitive data managed by the cloud does not have to leave your enterprise boundaries, keeping data completely protected from external access by your enterprise firewall.
Eucalyptus was designed from the ground up to be easy to install and non-intrusive. The software framework is modular, with industry-standard, language-agnostic communication. Eucalyptus is also unique in that it provides a virtual network overlay that isolates network traffic of different users as well as allows two or more clusters to appear to belong to the same Local Area Network (LAN).
Eucalyptus also is compatible with Amazon’s EC2, S3, and IAM services. This offers you hybrid cloud capability.
Eucalyptus supports two command line interfaces (CLIs): the administration CLI and the user CLI.The administration CLI is installed when you install Eucalyptus server-side components. The administration CLI is for maintaining and modifying Eucalyptus.
The other user CLI, called Euca2ools, can be downloaded and installed on clients. Euca2ools is a set of commands for end users and can be used with both Eucalyptus and Amazon Web Services (AWS).
After you install and initially configure Eucalyptus, there are some common administration tasks you can perform. This section describes these tasks and associated concepts.
This topic presents an overview of the components in Eucalyptus. Eucalyptus is comprised of several components: Cloud Controller, Walrus, Cluster Controller, Storage Controller, and Node Controller. Each component is a stand-alone web service. This architecture allows Eucalyptus both to expose each web service as a well-defined, language-agnostic API, and to support existing web service standards for secure communication between its components.
The Cloud Controller (CLC) is the entry-point into the cloud for administrators, developers, project managers, and end-users. The CLC queries other components for information about resources, makes high-level scheduling decisions, and makes requests to the Cluster Controllers (CCs). As the interface to the management platform, the CLC is responsible for exposing and managing the underlying virtualized resources (servers, network, and storage). You can access the CLC through command line tools that are compatible with Amazon’s Elastic Compute Cloud (EC2).
Walrus allows users to store persistent data, organized as buckets and objects. You can use Walrus to create, delete, and list buckets, or to put, get, and delete objects, or to set access control policies. Walrus is interface compatible with Amazon’s Simple Storage Service (S3). It provides a mechanism for storing and accessing virtual machine images and user data. Walrus can be accessed by end-users, whether the user is running a client from outside the cloud or from a virtual machine instance running inside the cloud.
The Cluster Controller (CC) generally executes on a machine that has network connectivity to both the machines running the Node Controller (NC) and to the machine running the CLC. CCs gather information about a set of NCs and schedules virtual machine (VM) execution on specific NCs. The CC also manages the virtual machine networks. All NCs associated with a single CC must be in the same subnet.
The Storage Controller (SC) provides functionality similar to the Amazon Elastic Block Store (Amazon EBS). Elastic block storage exports storage volumes that can be attached by a VM and mounted or accessed as a raw block device. EBS volumes persist past VM termination and are commonly used to store persistent data. An EBS volume cannot be shared between VMs and can only be accessed within the same availability zone in which the VM is running. Users can create snapshots from EBS volumes. Snapshots may be stored in Walrus and made available across availability zones.
The Node Controller (NC) executes on any machine that hosts VM instances. The NC controls VM activities, including the execution, inspection, and termination of VM instances. It also fetches and maintains a local cache of instance images, and it queries and controls the system software (host OS and the hypervisor) in response to queries and control requests from the CC. The NC is also responsible for the management of the virtual network endpoint.
This section details Eucalyptus best practices for your private cloud.
Eucalyptus checks message timestamps across components in the cloud infrastructure. This assures command integrity and provides better security.Eucalyptus components receive and exchange messages using either Query or SOAP interfaces (or both). Messages received over these interfaces are required to have some form of a time stamp (as defined by AWS specification) to prevent message replay attacks. Because Eucalyptus enforces strict policies when checking timestamps in the received messages, for the correct functioning of the cloud infrastructure, it is crucial to have clocks constantly synchronized (for example, with ntpd) on all machines hosting Eucalyptus components. To prevent user command failures, it is also important to have clocks synchronized on the client machines.
Following the AWS specification, all Query interface requests containing the Timestamp element are rejected as expired after 15 minutes of the timestamp. Requests containing the Expires element expire at the time specified by the element. SOAP interface requests using WS-Security expire as specified by the WS-Security Timestamp element.
When checking the timestamps for expiration, Eucalyptus allows up to 20 seconds of clock drift between the machines. This is a default setting. You can change this value for the CLC at runtime by setting the bootstrap.webservices.clock_skew_sec property as follows:
euctl bootstrap.webservices.clock_skew_sec=<new_value_in_seconds>
For additional protection from the message replay attacks, the CLC implements a replay detection algorithm and rejects messages with the same signatures received within 15 minutes. Replay detection parameters can be tuned as described in Configure Replay Protection .
In order to connect to Eucalyptus using SSL/TLS, you must have a valid certificate for the Cloud Controller (CLC)
If you have more than one host (other than node controllers), note the following:
Eucalyptus uses a PKCS12-format keystore. If you are using a certificate signed by a trusted root CA, use the following command to convert your trusted certificate and key into an appropriate format:
openssl pkcs12 -export -in [YOURCERT.crt] -inkey [YOURKEY.key] \
-out tmp.p12 -name [key_alias]
Save a backup of the Eucalyptus keystore, at /var/lib/eucalyptus/keys/euca.p12 , and then import your keystore into the Eucalyptus keystore as follows:
keytool -importkeystore \
-srckeystore tmp.p12 -srcstoretype pkcs12 -srcstorepass [export_password] \
-destkeystore /var/lib/eucalyptus/keys/euca.p12 -deststoretype pkcs12 \
-deststorepass eucalyptus -alias [key_alias] \
-srckeypass [export_password]
Run the following commands on the Cloud Controller (CLC):
euctl bootstrap.webservices.ssl.server_alias=[key_alias]
To allow user facing services requests on port 443 instead of the default 8773, run the following commands on the CLC:
euctl bootstrap.webservices.port=443
Eucalyptus manages storage volumes for your private cloud. Volume management strategies are application specific, but this topic includes some general guidelines.When setting up your Storage Controller, consider whether performance (bandwidth and latency of read/write operations) or availability is more important for your application. For example, using several smaller volumes will allow snapshots to be taken on a rolling basis, decreasing each snapshot creation time and potentially making restore operations faster if the restore can be isolated to a single volume. However, a single larger volume allows for faster read/write operations from the VM to the storage volume.
An appropriate network configuration is an important part of optimizing the performance of your storage volumes. For best performance, each Node Controller should be connected to a distinct storage network that enables the NC to communicate with the SC or Ceph, without interfering with normal NC/VM-instance network traffic.
Eucalyptus includes configurable limits on the size of a single volume, as well as the aggregate size of all volumes on an SC. The SC can push snapshots from Ceph, where the volumes reside, to object storage, where the snapshots become available across multiple clusters. Smaller volumes will be much faster to snapshot and transfer, whereas large volumes will take longer. However, if many concurrent snapshot requests are sent to the SC, operations may take longer to complete.
EBS volumes are created from snapshots on the SC or Ceph, after the snapshot has been downloaded from object storage to the device. Creating an EBS volume from a snapshot on the same cluster as the source volume of the snapshot will reduce delays caused by having to transfer snapshots from object storage.
This section contains a listing of your Eucalyptus cloud-related tasks.
Eucalyptus provides access to the current view of service state and the ability to manipulate the state. You can inspect the service state to either ensure system health or to identify faulty services. You can modify a service state to maintain activities and apply external service placement policies.
Use the euserv-describe-services command to view the service state. The output indicates:
-a flag.You can also make requests to retrieve service information that is filtered by either:
-events to return a summary of the last fault. You can retrieve extended information (primarily useful for debugging) by specifying -events -events-verbose .http://CLCIPADDRESS:8773/services/Heartbeat provides a list of components and their respective statuses. This allows you to find out if a service is enabled without requiring cloud credentials.
To modify a service:
Enter the following command on the CLC, Walrus, or SC machines:
systemctl stop eucalyptus-cloud.service
On the CC, use the following command:
systemctl stop eucalyptus-cluster.service
If you want to shut down the SC for maintenance. The SC is SC00 is ENABLED and needs to be DISABLED for maintenance.
To stop SC00 first verify that no volumes or snapshots are being created and that no volumes are being attached or detached, and then enter the following command on SC00:
systemctl stop eucalyptus-cloud.service
To check status of services, you would enter:
euserv-describe-services
When maintenance is complete, you can start the eucalyptus-cloud process on SC00 , which will enter the DISABLED state by default.
systemctl start eucalyptus-cloud.service
Monitor the state of services using euserv-describe-services until SC00 is ENABLED .
To see resource use by your cloud users, Eucalyptus provides the following commands with the flag.
You might want to change the original network configuration of your cloud. To change your network configuration, perform the tasks listed in this topic.Log in to the CLC and open the /etc/eucalyptus/eucalyptus.conf file. Navigate to the Networking Configuration section and make your edits. Save the file. Restart the Cluster Controller.
systemctl restart eucalyptus-cluster.service
All network-related options specified in /etc/eucalyptus/eucalyptus.conf use the prefix VNET_. The most commonly used VNET options are described in the following table.
| Option | Description | Component |
|---|---|---|
| VNET_BRIDGE | This is the name of the bridge interface to which instances’ network interfaces should attach. A physical interface that can reach the CC must be attached to this bridge. Common setting for KVM is br0. | Node Controller |
| VNET_DHCPDAEMON | The ISC DHCP executable to use. This is set to a distro-dependent value by packaging. The internal default is /usr/sbin/dhcpd3. | Node Controller |
| VNET_MODE | The networking mode in which to run. The same mode must be specified on all CCs and NCs in your cloud. Valid values: EDGE | All CCs and NCs |
| VNET_PRIVINTERFACE | The name of the network interface that is on the same network as the NCs. Default: eth0 | Node Controller |
| VNET_PUBINTERFACE | This is the name of the network interface that is connected to the same network as the CC. Depending on the hypervisor’s configuration this may be a bridge or a physical interface that is attached to the bridge. Default: eth0 | Node Controller |
If you want to increase your system’s capacity, you’ll want to add more Node Controllers (NCs).To add an NC, perform the following tasks:
Log in to the CLC and enter the following command:
clusteradmin-register-nodes node0_IP_address ... [nodeN_IP_address]
When prompted, enter the password to log into each node. Eucalyptus requires this password to propagate the cryptographic keys.
In order to ensure optimal system performance, or to perform system maintenance, it is sometimes necessary to move running instances between Node Controllers (NCs). You can migrate instances individually, or migrate all instances from a given NC.
euserv-migrate-instances -i INSTANCE_ID
You can also optionally specify --include-dest HOST_NC_IP or --exclude-dest HOST_NC_IP , to ensure that the instance is migrated to one of the specified NCs, or to avoid migrating the instance to any of the specified NCs. These flags may be used more than once to specify multiple NCs.
To migrate all instances away from an NC, enter the following command:
euserv-migrate-instances --source HOST_NC_IP
You can also optionally specify euserv-modify-service -s stop HOST_NC_IP , to stop the specified NC and ensure that no new instances are started on that NC while the migration occurs. This allows you to safely remove the NC without interrupting running instances. The NC will remain in the DISABLED state until it is explicitly enabled using euserv-modify-service -s start HOST_NC_IP .
In some cases, timeouts may cause a migration to initially fail. Run the command again to complete the migration.
If the migration fails, check the nc.log file on the source and destination NCs. If you see an error similar to:
libvirt: Cannot get interface MTU on 'br0': No such device (code=38)
… then ensure the NCs have the same interface and bridge device names, as described in .
Describes how to delete NCs in your system.If you want to decrease your system’s capacity, you’ll need to decrease NC servers. To delete an NC, perform the following tasks.
Log in to the CC and enter the following command:
clusteradmin-deregister-nodes node0_IP_address ... [nodeN_IP_address]
Describes the recommended processes to restart Eucalyptus, including terminating instances and restarting Eucalyptus components.You must restart Eucalyptus whenever you make a physical change (e.g., switch out routers), or edit the eucalyptus.conf file. To restart Eucalyptus, perform the following tasks in the order presented.
To terminate all instances on all NCs perform the steps listed in this topic. To terminate all instances on all NCs:
Enter the following command:
euca-terminate-instances <instance_id>
Log in to the CLC and enter the following command:
systemctl restart eucalyptus-cloud.service
All Eucalyptus components on this server will restart.
Log in to Walrus and enter the following command:
systemctl restart eucalyptus-cloud.service
Log in to the CC and enter the following command:
systemctl restart eucalyptus-cluster.service
Log in to the SC and enter the following command:
systemctl restart eucalyptus-cloud.service
To restart an NC perform the steps listed in this topic.Log in to the NC and enter the following command:
systemctl restart eucalyptus-node.service
Repeat for each NC. Verify that the following is even needed. If so, replicate for other NC-tasks. You can automate the restart command for all of your NCs. Store a list of your NCs in a file called nc-hosts that looks like:
nc-host-00
nc-host-01
...
nc-host-nn
To restart all of your NCs, run the following command:
cat nc-hosts | xargs -i ssh root@{} systemctl restart eucalyptus-node.service
Describes the recommended processes to shut down Eucalyptus.There may be times when you need to shut down Eucalyptus. This might be because of a physical failure, topological change, backing up, or making an upgrade. We recommend that you shut down Eucalyptus components in the reverse order of how you started them. To stop the system, shut down the components in the order listed.
To terminate all instances on all NCs perform the steps listed in this topic.To terminate all instances on all NCs:
Enter the following command:
euca-terminate-instances <instance_id>
To shut down the NCs perform the steps listed in this topic.To shut down the NCs:
Log in as root to a machine hosting an NC. Enter the following command:
systemctl stop eucalyptus-node.service
Repeat for each machine hosting an NC.
To shut down the CCs:
Log in as root to a machine hosting a CC. Enter the following command:
systemctl stop eucalyptus-cluster.service
Repeat for each machine hosting a CC.
To shut down the SC:
Log in as root to the physical machine that hosts the SC. Enter the following command:
systemctl stop eucalyptus-cloud.service
Repeat for any other machine hosting an SC.
To shut down Walrus:
Log in as root to the physical machine that hosts Walrus. Enter the following command:
systemctl stop eucalyptus-cloud.service
To shut down the CLC:
Log in as root to the physical machine that hosts the CLC. Enter the following command:
systemctl stop eucalyptus-cloud.service
To disable CloudWatch, run the following command.
euctl cloudwatch.enable_cloudwatch_service=true
This section contains concepts and tasks associated with operating your Eucalyptus cloud.
This section is for architects and cloud administrators who plan to deploy Eucalyptus in a production environment. It is not intended for end users or proof-of-concept installations.To run Eucalyptus in a production environment, you must be aware of your hardware and network resources. This guide is to help you make decisions about deploying Eucalyptus. It is also meant to help you keep Eucalyptus running smoothly.
To decide on your deployment’s scope, determine the use case for your cloud. For example, will this be a small dev-test environment, or a large and scalable web services environment?To help with scoping your deployment, see Plan Your Installation in the Installation Guide . There you will find solution examples and physical resource information.
This topic details what you should test when you want to make sure your deployment is working. The following suggested test plan contains tasks that ensure DNS, imaging, and storage are working.
This section describes the most commonly applied post-install customizations and the issues they pose:
Over-subscription refers to the practice of expanding your computer beyond its limits. Over-subscription applies only to node controllers. You may modify disks and cores to allow enough usage buffer for your instance. Navigate to /etc/eucalyptus/ and locate the eucalyptus.conf file. Edit the following values to define the appropriate size buffers for your instances: NC_WORK_SIZE Defines the amount of disk space available for instances to be run. Defaults to 1/3 of the currently available disk space on the NC, and NC_CACHE_SIZE defaults to the other 2/3.
NC_CACHE_SIZE Defines how much disk space is needed for images to be cached. MAX_CORES Defines the maximum number of cores that can be provided to VMs on each NC. If it is 0 or not present, then the only limit on the number of instances is the number of cores available on the NC. If it is present, any value greater than 256 is treated as 256. In order for these changes to take effect, you must restart the NC.
You can modify the default by adding network IPs to your cloud. Adding public IPs does not require shutting down the whole system.
To add network IPs:In EDGE mode, adding or changing the IP involves creating a JSON file and uploading it the Cloud Controller (CLC). See Configure for Edge Mode for more details. No restart needed, changes apply automatically.
You can change the following CloudWatch properties:
| Property | Description |
|---|---|
| cloud.monitor.default_poll_interval_mins | This is how often the CLC sends a request to the CC for sensor data. Default value is 5 minutes. If you set it to 0 = no reporting. The more often you poll, the more hit on system performance. |
| cloud.monitor.history_size | This is how many data value samples are sent in each sensor data request. The default value is 5. How many samples per poll interval. |
| cloudwatch.enable_cloudwatch_service | Disables CloudWatch when set to false. |
Capacity changes refer to adding another zone or more nodes. To add another zone, install , start , and register . To add more nodes, see Add a Node Controller .
This topic details best practices for managing your cloud policies.
This topic addresses networking in the Eucalyptus cloud.
Eucalyptus offers different modes to provide you with a cloud that will fit in your current network. For information what each networking mode has to offer, see Plan Networking Modes .
Eucalyptus EDGE networking mode supports EC2-Classic networking. Your instances run in a single, flat network that you share with others. For more information about EC2-Classic networking, see EC2 Supported Platforms .
Eucalyptus VPCMIDO networking mode resembles the Amazon Virtual Private Cloud (VPC) product wherein the network is fully configurable by users. For more information about EC2-VPC networking, see Differences Between Instances in EC2-Classic and EC2-VPC .
This topic includes details about which resources you should monitor.
| Component | Running Processes |
|---|---|
| Cloud Controller (CLC) | eucalyptus-cloud, postgres, eucanetd (VPCMIDO mode) |
| User-facing services (UFS) | eucalyptus-cloud |
| Walrus | eucalyptus-cloud |
| Cluster Controller (CC) | eucalyptus-cluster |
| Storage Controller (SC) | eucalyptus-sc, tgtd (for DAS and Overlay) |
| Node Controller (NC) | eucalyptus-node, httpd, dhcpd, eucanetd (EDGE mode), qemu-kvm / 1 per instance |
| Management Console | eucaconsole |
This section provides details on important files to back up and recover.
This section explains what you need to back up and protect your cloud data.We recommend that you back up the following data:
To back up the cloud database follow the steps listed in this topic.Bucket and object metadata are stored in the Eucalyptus cloud database. To back up the database
Log in to the CLC. The cloud database is on the CLC. Extract the Eucalyptus PostgreSQL database cluster into a script file.
pg_dumpall --oids -c -h/var/lib/eucalyptus/db/data -p8777 -U root -f/root/eucalyptus_pg_dumpall-backup.sql
Back up the cloud security credentials in the keys directory.
tar -czvf ~/eucalyptus-keydir.tgz /var/lib/eucalyptus/keys
This topic explains what to include when you recover your cloud.Recovering Your Cloud Data
To restore the cloud database follow the steps listed in this topic.
Stop the CLC service.
systemctl stop eucalyptus-cloud.service
Remove traces of the old database.
rm -rf /var/lib/eucalyptus/db
Restore the cloud security credentials in the keys directory.
tar -xvf ~/eucalyptus-keydir.tgz -C /
Re-initialize the database structure.
clcadmin-initialize-cloud
Start the database manually.
su eucalyptus -s /bin/bash -c "/usr/bin/pg_ctl start -w \
-s -D/var/lib/eucalyptus/db/data -o '-h0.0.0.0/0 -p8777 -i'"
Restore the backup.
psql -U root -d postgres -p 8777 -h /var/lib/eucalyptus/db/data -f/root/eucalyptus_pg_dumpall-backup.sql
Stop the database manually.
su eucalyptus -s /bin/bash -c "/usr/bin/pg_ctl stop -D/var/lib/eucalyptus/db/data"
Start CLC service
systemctl start eucalyptus-cloud.service
This topic details how to find information you need to troubleshoot most problems in your cloud. To troubleshoot Eucalyptus, you must have the following:
For most problems, the procedure for tracing problems is the same: start at the bottom to verify the bottom-most component, and then work your way up. If you do this, you can be assured that the base is solid. This applies to virtually all Eucalyptus components and also works for proactive, targeted monitoring.
Usually when an issue arises in Eucalyptus, you can find information that points to the nature of the problem either in the Eucalyptus log files or in the system log files. This topic details log file message meanings, location, configuration, and fault log information.
When you have to troubleshoot, it’s important to understand the elements of the network on your system.Here are some ideas for finding out information about your network:
This section describes common problems and workarounds.
Use ping from a client (not the CLC). Can you ping it?
Yes: Check the open ports on security groups and retry connection using SSH or HTTP. Can you connect now? Yes. Okay, then. You’re work is done. No: Try the same procedure as if you can’t ping it up front. No: Is your cloud running in Edge networking mode?
Yes: Run euca-describe-nodes . Is your instance there?
No, it is not in Edge networking mode:
Eucalyptus offers installation checks for any Eucalyptus component or service (CLC, Walrus, SC, NC, SC, services, and more). When Eucalyptus encounters an error, it presents the problem to the operator. These checks are used for install-time problems. They provide resolutions to some of the fault conditions.
Each problematic condition contains the following information:
| Heading | Description |
|---|---|
| Condition | The fault found by Eucalyptus |
| Cause | The cause of the condition |
| Initiator | What is at fault |
| Location | Where to go to fix the fault |
| Resolution | The steps to take to resolve the fault |
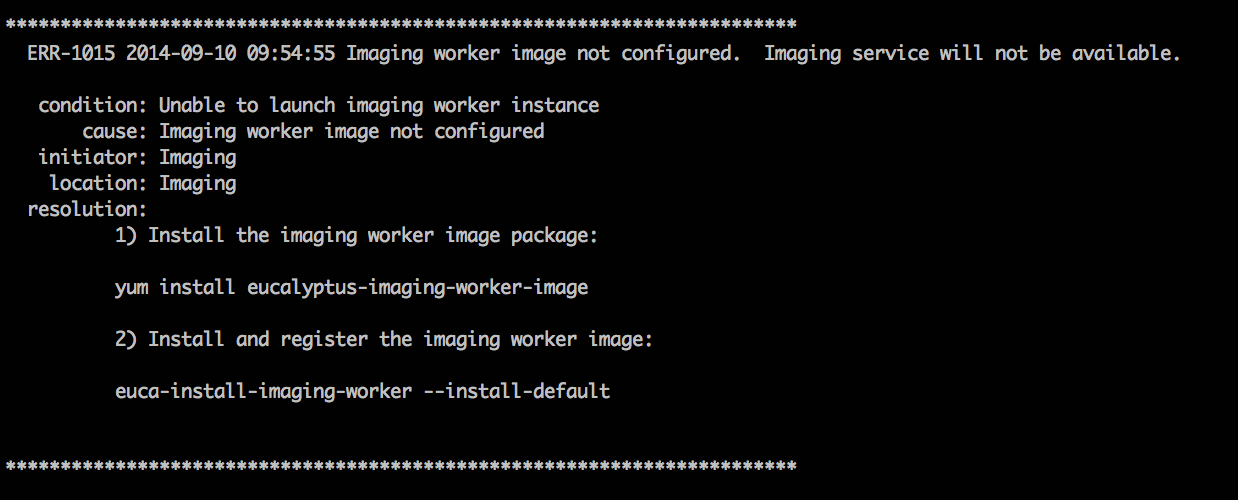
For more information about all the faults we support, go to https://github.com/eucalyptus/eucalyptus/tree/master/util/faults/en_US .
Run euca-describe-nodes to verify if instance is there. Is the instance there?
Yes: Go to the NC log for that NC and grep your instance ID. Did you find the instance?
No: Go to the CC log and grep the instance ID. Is it there error message?
Yes: The error message should give you some helpful information.
No: grep the instance ID in cloud-output.log . Is there error message?
No: Log in as admin and run euca-describe-instance . Is the instance there?
On the SC, depending on the backend used for storage:
Yes: On the OSG host, depending on the backend used for object storage:
For Walrus, use the command to check the disk space in .
For RiakCS or Ceph-RGW, use its specific commands to check the free space for storage allocated for buckets and objects. Is there enough space? Yes.
Use and note the IP addresses for the OSG and SC.
SSH to SC and ping the OSG. Are there error messages?
No: Delete volumes or add disk space. No: Delete volumes or add disk space.
Symptom: Went from available to fail. This is typically caused by the CLC and the SC.On the SC, use df or lvdisplay to check the disk space. Is there enough space?
Yes: Check the SC log and grep the volume ID. Is there error message? Yes. This provides clues to helpful information. No: Check cloud-output.log for a volume ID error. No: Delete volumes or add disk space.
This section contains troubleshooting information for Eucalyptus components and services.
This topic contains information about access-related problems and solutions. Need to verify an existing LIC file.
This topic explains suggestions for problems you might have with Elastic Load Balancing (ELB).
Can’t synchronize with time server
Eucalyptus sets up NTP automatically for any instance that has an internet connection to a public network. If an instance doesn’t have such a connection, set the cloud property loadbalancing.loadbalancer_vm_ntp_server to a valid NTP server IP address. For example:
euctl loadbalancing.loadbalancer_vm_ntp_server=169.254.169.254
PROPERTY loadbalancing.loadbalancer_vm_ntp_server 169.254.169.254 was {}
Need to debug an ELB instance
To debug an ELB instance, set the loadbalancing.loadbalancer_vm_keyname cloud property to the keypair of the instance you want to debug. For example:
# euctl loadbalancing.loadbalancer_vm_keyname=sshlogin
PROPERTY loadbalancing.loadbalancer_vm_keyname sshlogin was {}
This topic contains troubleshooting tips for the Imaging Worker.Some requests that require the Imaging Worker might remain in pending for a long time. For example: an import task or a paravirtual instance run. If request remains in pending, the Imaging Worker instance might not able to run because of a lack of resources (for example, instance slots or IP addresses).
You can check for this scenario by listing latest AutoScaling activities:
euscale-describe-scaling-activities -g asg-euca-internal-imaging-worker-01
Check for failures that indicate inadequate resources such as:
ACTIVITY 1950c4e5-0db9-4b80-ad3b-5c7c59d9c82e 2014-08-12T21:05:32.699Z asg-euca-internal-imaging-worker-01 Failed Not enough resources available: addresses; please stop or terminate unwanted instances or release unassociated elastic IPs and try again, or run with private addressing only
This topic contains information to help you troubleshoot your instances. Inaccurate IP addresses display in the output of euca-describe-addresses. This can occur if you add IPs from the wrong subnet into your public IP pool, do a restart on the CC, swap out the wrong ones for the right ones, and do another restart on the CC. To resolve this issue, run the following commands.
systemctl stop eucalyptus-cloud.service
systemctl stop eucalyptus-cluster.service
iptables -F
systemctl restart eucalyptus-cluster.service
systemctl start eucalyptus-cloud.service
NC does not recalculate disk size correctly This can occur when trying to add extra disk space for instance ephemeral storage. To resolve this, you need to delete the instance cache and restart the NC.
For example:
rm -rf /var/lib/eucalyptus/instances/*
systemctl restart eucalyptus-node.service
This topic contains information about Walrus-related problems and solutions. Walrus decryption failed. On Ubuntu 10.04 LTS, kernel version 2.6.32-31 includes a bug that prevents Walrus from decrypting images. This can be determined from the following line in cloud-output.log
javax.crypto.
BadPaddingException: pad block corrupted
If you are running this kernel:
Walrus physical disk is not large enough.
This section includes tasks to help you manage your users’ cloud resources.
You can list, delete, update, and suspend your Eucalyptus cloud’s Autoscaling resources by passing the option with the keyword with the appropriate command.The followings are some examples you can use to act on your Auto Scaling resources.
To show all launch configurations in your cloud, run the following command:
euscale-describe-launch-configs --show-long verbose
To show all Auto Scaling instances in your cloud, run the following command:
euscale-describe-auto-scaling-groups --show-long verbose
To show all Auto Scaling instances in your cloud, run the following command:
euscale-describe-auto-scaling-groups --show-long verbose
To delete an Auto Scaling resource in your cloud, first get the ARN of the resource, as in this example:
$ euscale-describe-launch-configs --show-long verbose
LAUNCH-CONFIG TestLaunchConfig emi-06663A57 m1.medium 2013-10-30T22:52:39.392Z true
arn:aws:autoscaling::961915002812:launchConfiguration:5ac29caf-9aad-4bdb-b228-5f
ce841dc062:launchConfigurationName/TestLaunchConfig
Then run the following command with the ARN:
euscale-delete-launch-config
arn:aws:autoscaling::961915002812:launchConfiguration:5ac29caf-9aad-4bdb-b228-5f
ce841dc062:launchConfigurationName/TestLaunchConfig
To manage CloudWatch resources on a Eucalyptus cloud, use the option in any command that lists, deletes, modifies, or sets a CloudWatch resource.The following are examples of what you can do with your CloudWatch resources.
To list all alarms for the cloud, run the following command:
euwatch-describe-alarms verbose
To manage compute resources on a Eucalyptus cloud, use the option in any command.The following are some examples you can use to view various compute resources.
To see all instances running on your cloud, enter the following command:
euca-describe-instances verbose
To see all volumes in your cloud, enter the following command:
euca-describe-volumes verbose
To see all keypairs in your cloud, enter the following command:
euca-describe-keypairs verbose
To list and delete ELB resources on a Eucalyptus cloud, use the option with any command.The following are some examples.
To list all detailed configuration information for the load balancers in your cloud, run the following command:
eulb-describe-lbs verbose
To list the details of policies for all load balancers in your cloud, run the following command:
eulb-describe-lb-policies verbose
To list meta information for all load balancer policies in your cloud, run the following command:
eulb-describe-lb-policy-types verbose
To delete any load balancer or any load balancer resource on the cloud, instead of using the ELB name, use the DNS name. For example:
$ eulb-describe-lbs verbose
LOAD_BALANCER MyLoadBalancer MyLoadBalancer-961915002812.lb.foobar.eucalyptus-systems.com 2013-10-30T03:02:53.39Z
$ eulb-delete-lb MyLoadBalancer-961915002812.lb.foobar.eucalyptus-systems.com
$ eulb-describe-lbs verbose
To manage Euare (IAM) resources on your Eucalyptus cloud, use the option with any command that describes, adds, deletes, or modifies resources. This option allows you to assume the role of the admin user for a given account. You can also use a policy to control and limit instances to specific availability zones. The following are some examples.
To list all groups in an account, enter the following command:
euare-grouplistbypath --as-account <account-name>
To list all users in an account, enter the following command:
euare-userslistbypath --as-account <account-name>
To delete the login profile of a user in an account, enter the following command:
euare-userdelloginprofile --as-account <account-name> -u <user_name>
To modify the login profile of a user in an account, enter the following command:
euare-usermod --as-account <account-name> -u <user_name> -n
<new_user_name>
To restrict an image to a specific availability zone, edit and attach this sample policy to a user:
{
"Statement":[
{
"Effect":"Allow",
"Action":"ec2:*",
"Resource":"*"
},
{
"Effect": "Deny",
"Action": [ "ec2:*" ],
"Resource": "arn:aws:ec2:::availabilityzone/PARTI00",
"Condition": {
"ArnLike": {
"ec2:TargetImage": "arn:aws:ec2:*:*:image/emi-239D37F2"
}
}
}
]
}
To restrict a user to actions only within a specific availability zone, edit and attach this sample policy to a user:
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": [ "ec2:TerminateInstances" ],
"Resource": "*",
"Condition": {
"StringEquals": {
"ec2:AvailabilityZone": "PARTI00"
}
}
}]
}
To deny actions at the account level, edit and attach this example policy to an account:
{
"Statement": [ {
"Effect": "Deny",
"Action": [ "ec2:RunInstances" ],
"Resource": "arn:aws:ec2:::availabilityzone/PARTI00",
"Condition": {
"ArnLike": {
"ec2:TargetImage": "arn:aws:ec2:*:*:image/emi-239D37F2"
}
}
} ]
}
This topic explains Walrus resources.
For more information about IAM policies, go to Using IAM Policies .
This section provides information about regions and identity federation.
Eucalytpus provides support for the notion of federation of identity.Federation of identity information means that a Cloud Administrator can create a federation of (otherwise independent) Eucalyptus “clouds” where a Cloud User, using the same credentials as always, can use any of these federated Eucalyptus cloud regions. For the parts of Identify Access Management (IAM) and Security Token Service (STS) that Eucalyptus implements, the experience exposed to the Cloud User is the same as that seen by an AWS user working across AWS regions.
A user can interact with any region using the same credentials, subjected to the same policies, and having uniformly accessible and structured principals (Accounts, Users, Groups, Roles, etc.). The globality also includes the STS service functionality, the temporary credentials produced by the STS service also work globally.
Notably, this feature is restricted to IAM/STS and does not include other services which have pseudo-global characteristics, such as global bucket name space for S3. The following are general principles associated with regions:
This section describes the necessary configuration properties that need to be addressed.For federation to be successfully configured, each cloud (i.e. region) that will be part of the federated cloud needs to have the following properties set (at a minimum):
| Property Name | Description |
|---|---|
| region.region_name | This cloud property identifies the local region. This is required and should be valid for use in a DNS name. |
| region.region_configuration | This property is a JSON document that will be the same for all federated regions. |
In this example, there will be two clouds used (10.111.5.32 and 10.111.1.1). Before setting up federation, the clouds must meet the following requirements:
This section outlines the differences between AWS and Eucalyptus with respect to federation in the following platforms:
This section is presented in a Q&A format to provide a quick reference to the most frequently asked questions.
Can Cloud Administrators federate existing clouds (i.e. clouds that already have non-system Eucalyptus accounts)? A. No, this is currently not supported. If a cloud administrator wants to federate an Eucalyptus clouds, this must be done prior to any non-system Eucalyptus account/user/group creation.
Is Eucalyptus DNS required for federating Eucalyptus clouds? A. No, however its highly recommended to enable it.
Are supported for more granular IAM access policies per region? A. As of 4.2, no. IAM policies apply globally (for all regions). In order to get more granular IAM access, use availability zone restrictions under each region. For more information, see Restrict Image to Availability Zone .
What services/resources span globally? Which span regionally? A. Currently, only Eucalyptus IAM and STS are global services/resources. All other services/resources are region-based (i.e. Eucalyptus cloud-specific). The only resource that can be either global or regional are keypairs. This is because users can import the same keypair to each region, therefore, the keypair is globally accessible. For additional information, please refer to the AWS EC2 Documentation regarding Resource Locations .
Are Eucalyptus system accounts global in a federated setup? A. No. Any Eucalyptus system account is limited to that region. Examples of Eucalyptus system accounts are as follows:
Is and supported? A. No. There have been no improvements associated with Object Storage Gateway (OSG) regarding cross-regional behavior similar to AWS.
If a user uploads an object to an Object Storage Gateway in one region, will copies show up in other regions (similar to the behavior on AWS)? A. No, this is currently unsupported.
Do federated Eucalyptus clouds follow the same globally? A. No, Eucalyptus IAM limitations are regionally scoped.
This section details concepts and tasks required to secure your cloud.
This topic is intended for people who are currently using Eucalyptus and who want to harden the cloud and underlying configuration.
This topic covers available controls and best practices for securing your Eucalyptus cloud. Cloud security depends on security across many layers of infrastructure and technology:
This topic contains recommendations for hardening your Eucalyptus cloud.
This topic describes best practices for Identity and Access Management and the account.
Eucalyptus manages access control through an authentication, authorization, and accounting system. This system manages user identities, enforces access controls over resources, and provides reporting on resource usage as a basis for auditing and managing cloud activities. The user identity organizational model and the scheme of authorizations used to access resources are based on and compatible with the AWS Identity and Access Management (IAM) system, with some Eucalyptus extensions provided that support ease-of-use in a private cloud environment.
For a general introduction to IAM in Eucalyptus, see Access Concepts in the IAM Guide. For information about using IAM quotas to enforce limits on resource usage by users and accounts in Eucalyptus, see the Quotas section in the IAM Guide.
The Amazon Web Services IAM Best Practices are also generally applicable to Eucalyptus.
Protection and careful management of user credentials (passwords, access keys, X.509 certificates, and key pairs) is critical to cloud security. When dealing with credentials, we recommend:
The eucalyptus account is a super-privileged account in Eucalyptus. It has access to all cloud resources, cloud setup, and management. The users within this account do not obey IAM policies and compromised credentials can result in a complete cloud compromisation that is not easy to contain. We recommend limiting the use of this account and associated users’ credentials as much as possible.
For all unprivileged operations, use regular accounts. If you require super-privileged access (for example, management of resources across accounts and cloud setup administration), we recommend that you use one of the predefined privileged roles.
The Account, Infrastructure, and Resource Administrator roles provide a more secure way to gain super privileges in the cloud. Credentials returned by an assume-role operation are short-lived (unlike regular user credentials). Privileges available to each role are limited in scope and can be revoked easily by modifying the trust or access policy for the role.
This topic describes best practices for machines that host a Eucalyptus component.Eucalyptus recommends restricting physical and network access to all hosts comprising the Eucalyptus cloud, and disabling unused applications and ports on all machines used in your cloud.
After installation, no local access to Eucalyptus component hosts is required for normal cloud operations and all normal cloud operations can be done over remote web service APIs.
The user-facing services (UFS) and object storage gateway (OSG) are the only two components that generally expect remote connections from end users. Each Eucalyptus component can be put behind a firewall following the list of open ports and connectivity requirements described in the Configure the Firewall section.
For more information on securing Red Hat hosts, see the Red Hat Enterprise Linux Security Guide .
Because all instances are based on images, creating a secure image helps to create secure instances. This topic lists best practices that will add additional security during image creation. As a general rule, harden your images similar to how you would harden your physical servers.
euca-authorize and euca-revoke .Consider creating one security group that allows external logins and keep the remainder of your instances in a group that does not allow external logins. Review the rules in your security groups regularly, and ensure that you apply the principle of least privilege: only open up permissions as they are required. Use different security groups to deal with instances that have different security requirements.
This topic describes things you can do to secure the Eucalyptus Management Console.
This topic describes which networking mode is the most secure, and describes how to enforce message security.
Eucalyptus components receive and exchange messages using either Query or SOAP interfaces (or both). Messages received over these interfaces are required to have a time stamp (as defined by AWS specification) to prevent message replay attacks. Because Eucalyptus enforces strict policies when checking timestamps in the received messages, for the correct functioning of the cloud infrastructure, it is crucial to have clocks constantly synchronized (for example, with ntpd) on all machines hosting Eucalyptus components. To prevent user commands failures, it is also important to have clocks synchronized on the client machines.
Following the AWS specification, all Query interface requests containing the Timestamp element are rejected as expired after 15 minutes of the timestamp. Requests containing the Expires element expire at the time specified by the element. SOAP interface requests using WS-Security expire as specified by the WS-Security Timestamp element.
Replay detection parameters can be tuned as described in Configure Replay Protection .
Eucalyptus requires that all user requests (SOAP with WS-Security and Query) are signed, and that their content is properly hashed, to ensure integrity and non-repudiation of messages. For stronger security, and to ensure message confidentiality and server authenticity, client tools and applications should always use SSL/TLS protocols with server certification verification enabled for communications with Eucalyptus components.
By default, Eucalyptus components are installed with self-signed certificates. For public Eucalyptus endpoints, certificates signed by a trusted CA provider should be installed.
This topic describes the recommendations for networking modes.A Eucalyptus deployment can be configured in EDGE (AWS EC2 Classic compatible) or VPCMIDO (AWS VPC compatible) networking modes. In both modes, by default, instances are not allowed to send traffic with spoofed IP and/or MAC addresses and receive traffic that are not destined to their own IP and/or MAC addresses. Security groups should be used to control the ingress traffic to instances (EDGE and VPCMIDO modes) and to control the egress traffic from instances (VPCMIDO mode).
VPCMIDO mode offers many security features not present in EDGE mode. Instances of different accounts are deployed in user-defined isolated networks within a Eucalyptus cloud. A combination of security features including VPC, VPC subnets, security groups, source/destination check configuration, route tables, internet gateways, and NAT gateways can be used to selectively enable and configure network access to/from instances or group of instances.
For more information about choosing a networking modes, see Plan Networking Modes .
This section details the tasks needed to make your cloud secure.
In order to connect to Eucalyptus using SSL, you must have a valid certificate for the User-Facing Services (UFS).
You can use secure HTTP for your console.To run your console over Secure HTTP:
Install nginx on your console server with the following command: yum install nginx Overwrite the default nginx.conf file with the template provided in /usr/share/doc/eucaconsole-/nginx.conf. cp /usr/share/doc/eucaconsole-/nginx.conf /etc/nginx/nginx.conf Uncomment the ’listen’ directive and uncomment/modify the SSL certificate paths in /etc/nginx/nginx.conf (search for “SSL configuration”). For example:
# SSL configuration
listen 443 ssl;
# ssl_certificate /path/to/ssl/pem_file;
# EXAMPLE:
ssl_certificate /etc/eucaconsole/console.crt;
# ssl_certificate_key /path/to/ssl/certificate_key;
# EXAMPLE:
ssl_certificate_key /etc/eucaconsole/console.key;
# end of SSL configuration
systemctl restart nginx.service Edit the /etc/eucaconsole/console.ini file, locate the session.secure = false parameter, change false to true , then add the sslcert and sslkey lines immediately following, per this example:session.secure = true
sslcert=/etc/eucaconsole/eucalyptus.com.chained.crt
sslkey=/etc/eucaconsole/eucalyptus.com.key
This topic details tasks to configure SSL/TLS for the User-Facing Services (UFS)
If you have more than one host (other than node controllers), note the following:
Eucalyptus uses a PKCS12-format keystore. If you are using a certificate signed by a trusted root CA, perform the following steps.
Enter the following command to convert your trusted certificate and key into an appropriate format:
openssl pkcs12 -export -in [YOURCERT.crt] -inkey [YOURKEY.key] \
-out tmp.p12 -name [key_alias]
Save a backup of the Eucalyptus keystore, at /var/lib/eucalyptus/keys/euca.p12 . Import your keystore into the Eucalyptus keystore on the UFS:
keytool -importkeystore -srckeystore tmp.p12 -srcstoretype pkcs12 \
-srcstorepass [export_password] -destkeystore /var/lib/eucalyptus/keys/euca.p12 \
-deststoretype pkcs12 -deststorepass eucalyptus -alias [key_alias] -destkeypass eucalyptus
To enable the UFS to use the keystore, perform the following steps in the CLC because the UFS gets all its configuration information from the CLC. Run the following commands on the CLC:
euctl bootstrap.webservices.ssl.server_alias=[key_alias]
To allow user facing services requests on port 443 instead of the default 8773, run the following commands on the CLC:
euctl bootstrap.webservices.port=443
This topic describes how to change your multicast address for group membership.By default, Eucalyptus uses the multicast address 239.193.7.3 for group membership. Most data centers limit multicast address communication for security measures. We recommend that you use addresses in the administratively-scoped multicast address range.
To change the multicast address for group membership Stop all services, starting from the CC, SC, Walrus, then CLC. For example:
systemctl stop eucalyptus-cluster.service
systemctl stop eucalyptus-cloud.service
Change the eucalyptus.conf on the CC, modifying the CLOUD_OPTS parameter to the new IP address:
CLOUD_OPTS="--mcast-addr=228.7.7.3"
systemctl start eucalyptus-cloud.service
systemctl start eucalyptus-cluster.service
Verify that the configured multicast address is being used via netstat:
netstat -nulp
Postrequisites
You can configure replay detection in Java components (which includes the CLC, UFS, OSG, Walrus, and SC) to allow replays of the same message for a set time period.
bootstrap.webservices.replay_skew_window_sec property. The default value of this property is 3 seconds. To change this value, enter the following command:euctl bootstrap.webservices.replay_skew_window_sec=[new_value_in_seconds]
If you set this property to 0 , Eucalyptus will not allow any message replays. This setting provides the best protection against message replay attacks.
If you set this property to any value greater than 15 minutes plus the values of ws.clock_skew_sec (that is, to a value >= 920 sec in the default installation), Eucalyptus disables replay detection completely.
When checking message timestamps for expiration, Eucalyptus allows up to 20 seconds of clock drift between the machines. This is a default setting. You can change this value for the Java components at runtime by setting the bootstrap.webservices.clock_skew_sec property as follows:
euctl bootstrap.webservices.clock_skew_sec=[new_value_in_seconds]
To set the session timeouts in the Management Console:
Modify the session.timeout and session.cookie_expires entries in the [app:main] section of the configuration file. The session.timeout value defines the number of seconds before an idle session is timed out. The session.cookie_expires is the maximum length that any session can be active before being timed out. All values are in seconds:
session.timeout=1800
session.cookie_expires=43200
The Security Token Service (STS) allows you to enable or disable specific token actions.By default, the enabled actions list is empty. However, this means that all actions are enabled. To disable actions, list each action in the disabledactions property. To enable specific actions, list them in the enabledactions property.
# euctl tokens
PROPERTY tokens.disabledactions {}
PROPERTY tokens.enabledactions {}
The values for each property are case-insensitive, space or comma-separated lists of token service actions. If an action is in the disable list it will not be permitted. Eucalyptus returns an HTTP status 503 and the code ServiceUnavailable .
If the enable list is not empty, Eucalyptus only permits the actions specifically listed.
| Action | Description |
|---|---|
| AssumeRole | Roles as per AWS/STS and Eucalyptus-specific personas admin functionality |
| GetAccessToken | Eucalyptus extension for password logins (for example, the Management Console) |
| GetImpersonationToken | Eucalyptus extension that allows cloud administrators to act as specific users |
| GetSessionToken | Session tokens in the sameas per AWS/STS |
For more information about STS, go to STS section of the AWS CLI Reference .
This section provides basic guidance on setting up a firewall around your Eucalyptus components. It is not intended to be exhaustive.
On the Cloud Controller (CLC), Walrus, and Storage Controller (SC), allow for the following jGroups traffic:
TCP connections between CLC, user-facing services (UFS), object storage gateway (OSG), Walrus, and SC on port 8779 (or the first available port in range 8779-8849)
UDP connections between CLC, UFS, OSG, Walrus, and SC on port 7500
Multicast connections between CLC and UFS, OSG, Walrus, and SC to IP 239.193.7.3 on UDP port 8773 On the UFS, allow the following connections:
TCP connections from end-users and instances on ports 8773
End-user and instance connections to DNS ports On the CLC, allow the following connections:
TCP connections from UFS, CC and Eucalyptus instances (public IPs) on port 8773 (for metadata service)
TCP connections from UFS, OSG, Walrus, and SC on port 8777 On the CC, make sure that all firewall rules are compatible with the dynamic changes performed by Eucalyptus, described in the section below. Also allow the following connections:
TCP connections from CLC on port 8774 On OSG, allow the following connections:
TCP connections from end-users and instances on port 8773
TCP connections from SC and NC on port 8773 On Walrus, allow the following connections:
TCP connections from OSG on port 8773 On the SC, allow the following connections:
TCP connections from CLC and NC on TCP port 8773
TCP connections from NC on TCP port 3260, if tgt (iSCSI open source target) is used for EBS in DAS or Overlay modes On the NC, allow the following connections:
TCP connections from CC on port 8775
TCP connections from other NCs on port 16514
DHCP traffic forwarding to VMs
Traffic forwarding to and from instances’ private IP addresses
| Port | Description |
|---|---|
| TCP 5005 | DEBUG ONLY: This port is used for debugging (using the –debug flag). |
| TCP 8772 | DEBUG ONLY: JMX port. This is disabled by default, and can be enabled with the –debug or –jmx options for CLOUD_OPTS. |
| TCP 8773 | Web services port for the CLC, user-facing services (UFS), object storage gateway (OSG), Walrus SC; also used for external and internal communications by the CLC and Walrus. Configurable with euctl. |
| TCP 8774 | Web services port on the CC. Configured in the eucalyptus.conf configuration file |
| TCP 8775 | Web services port on the NC. Configured in the eucalyptus.conf configuration file. |
| TCP 8777 | Database port on the CLC |
| TCP 8779 (or next available port, up to TCP 8849) | jGroups failure detection port on CLC, UFS, OSG, Walrus SC. If port 8779 is available, it will be used, otherwise, the next port in the range will be attempted until an unused port is found. |
| TCP 8888 | The default port for the Management Console. Configured in the /etc/eucalyptus-console/console.ini file. |
| TCP 16514 | TLS port on Node Controller, required for instance migrations |
| UDP 7500 | Port for diagnostic probing on CLC, UFS, OSG, Walrus SC |
| UDP 8773 | Membership port for any UFS, OSG, Walrus, and SC |
| UDP 8778 | The bind port used to establish multicast communication |
| TCP/UDP 53 | DNS port on UFS |
| UDP 63822 | eucanetd binds to localhost port 63822 and uses it to detect and avoid running multiple instances (of eucanetd) |
To synchronize your Eucalyptus component machines with an NTP server, perform the following tasks.
Enter the following command on a machine hosting a Eucalyptus component:
# ntpdate pool.ntp.org
# systemctl start ntpd.service
# systemctl enable ntpd.service
# ps ax | grep ntp
# hwclock --systohc
Repeat for each machine hosting a Eucalyptus component.
This section contains reference information for Eucalyptus administration commands.
Eucalyptus offers commands for common administration tasks and inquiries. This section provides a reference for these commands.
euctl [-Anr] [-d | -s] NAME ...
euctl [-nq] NAME=VALUE ...
euctl [-nq] NAME=@FILE ...
euctl --dump [--format {raw,json,yaml}] NAME
euctl --edit [--format {raw,json,yaml}] NAME
| Argument | Description |
|---|---|
| NAME | Output a variable’s value. |
| NAME=VALUE | Set a variable to the specified value and then output it. |
| NAME=@FILE | Set a variable to that of the specified file’s contents, then output it. |
| Option | Description | Required |
|---|---|---|
| -A, –all-types | List all the known variable names, including structures. Those with string or integer values will be output as usual; for the structured values, the methods of retrieving them are given. | No |
| -d | Output variables’ default values rather than their current values. Note that not all variables have default values. | No |
| -s | Show variables’ descriptions instead of their current values. | No |
| -n | Suppress output of the variable name. This is useful for setting shell variables. | No |
| -q | Suppress all output when setting a variable. This option overrides the behavior of the -n parameter. | No |
| -r, –reset | Reset the given variables to their default values. | No |
| –dump | Output the value of a structured variable in its entirety. The value will be formatted in the manner specified by the –format option. | No |
| –edit | Edit the value of a structure variable interactively. The value will be formatted in the manner specified by the –format option. Only one variable may be edited per invocation. When looking for an editor, the program will first try the environment variable VISUAL, then the environment variable EDITOR, and finally the default editor, vi. | No |
| –format {raw,json,yaml} | Use the specified format when displaying a structured variable.Valid values: raw | json |
When retrieving a variable, a subset of the MIB name may be specified to retrieve a list of variables in that subset. For example, to list all the dns variables:
euctl dns
This replaces euca-describe-properties .
When setting a variable, the MIB name should be followed by an equal sign and the new value:
euctl dns.enabled=true
This replaces euca-modify-property -p .
To write variables using the contents of the files as their new values rather than typing them into the command line, follow them with =@ and those file names:
euctl cloud.network.network_configuration=@/etc/eucalyptus/network.yaml
This replaces euca-modify-property -f .
Specify a filename to read the values from a file:
myproperty=@myvaluefile
It is possible to read or write more than one variable in a single invocation of euctl . Just separate them with spaces:
euctl one=1 two=2 three four=@4.txt five
In all of these cases, euctl will generally output each variable named on its command line, along with its current (and potentially just-changed) value. For example, the output of the command above could be:
one = 1
two = 2
three = 3
four = 4
five = 5
To reset a variable to its default value, specify the -r option:
euctl -r dns.enabled
The information available from euctl consists of integers, strings, and structures. The structured information can only be retrieved by specialized programs and, in some cases, this program’s --edit and --dump options.
euserv-deregister-service [-U URL] [--region USER@REGION] [-I KEY_ID]
[-S KEY] [--security-token TOKEN] [--debug]
[--debugger] [--version] [-h] SVCINSTANCE
| Argument | Description |
|---|---|
| SVCINSTANCE | Name of the service instance to de-register. |
Eucalyptus returns a message stating that service instance was successfully de-registered.
To de-register the dns service named “API_10.111.1.44.dns”:
euserv-deregister-service API_10.111.1.44.dns
euserv-describe-events [-s] [-f FORMAT]
Events come in the form of a list, where each event contains one or more of the following tags:
| Tag | Description |
|---|---|
| id | A unique ID for the event. |
| message | A free-form text description of the event. |
| severity | The message’s severity (FATAL, URGENT, ERROR, WARNING, INFO, DEBUG, TRACE). |
| stack-trace | The stack trace, if any, corresponding to the event. The -s option is required to make this appear. |
| subject-arn | The Eucalyptus ARN of the service affected by the event. |
| subject-name | The name of the service affected by the event. |
| subject-type | The type of service affected by the event. |
| timestamp | The date and time of the event’s creation. |
| Environment | Description |
|---|---|
| AWS_ACCESS_KEY_ID | The access key ID to use when authenticating web service requests. This takes precedence over and euca2ools.ini, but not -I. |
| AWS_SECRET_ACCESS_KEY | The secret key to use when authenticating web service requests. This takes precedence over –region and euca2ools.ini(5), but not -S. |
| EUCA_BOOTSTRAP_URL | The URL of the service to contact. This takes precedence over –region and euca2ools.ini, but not -U. |
There are several built-in formats, and you can define additional formats using a format: string , as described below. Here are the details of the built-in formats:
yaml This outputs block-style YAML designed to be easily readable. Tags that are empty or not defined do not appear in this output at all.
events:
- timestamp: {timestamp}
severity: {severity}
id: {id}
subject-type: {subject-type}
subject-name: {subject-name}
subject-host: {subject-host}
subject-arn: {subject-arn}
message: |-
{message}
stack-trace: |-
{stack-trace}
oneline This output is designed to be as compact as possible.
{timestamp} {severity} {subject-type} {subject-name} {message}
format:string
The format: string format allows you to specify which information you want to show using placeholders enclosed in curly braces to indicate where to show the tags for each event. For example:
euserv-describe-events -f "format:{timestamp} {subject-name} {message}"
To output a list of service-affecting events in the oneline format:
euserv-describe-events --format oneline
2016-06-20 16:16:08 INFO node 10.111.1.15 the node is operating normally\nFound service status for 10.111.1.15: ENABLED
2016-06-27 17:37:57 ERROR node 10.111.5.50 Error occurred in transport
2016-06-28 07:00:17 ERROR node 10.111.5.50
euserv-describe-node-controllers [--ec2-url URL] [--show-headers]
[--show-empty-fields] [-U URL]
[--region USER@REGION] [-I KEY_ID] [-S KEY] [--security-token
TOKEN] [--debug] [--debugger] [--version] [-h]
| Option | Description | Required |
|---|---|---|
| –ec2-url url | The compute service’s endpoint URL. | No |
| –show-headers | Show column headers. | No |
Eucalyptus returns information about the node controller and its instances, for example:
NODE one 10.111.1.53 enabled
INSTANCE i-162a8f09
INSTANCE i-2b6cdd10
NODE one 10.111.5.132 enabled
INSTANCE i-ba9307d7
euserv-describe-node-controllers --region localhost
euserv-describe-service-types [-a] [--show-headers]
[--show-empty-fields] [-U URL]
[--region USER@REGION] [-I KEY_ID] [-S KEY] [--security-token TOKEN]
[--debug] [--debugger] [--version] [-h]
| Option | Description | Required |
|---|---|---|
| -a, –all | Show all service types regardless of their properties. | No |
| –show-headers | Show column headers. | No |
Eucalyptus returns a list of service types.
euserv-describe-service-types
SVCTYPE arbitrator The Arbitrator service
SVCTYPE autoscaling user-api Auto Scaling API service
SVCTYPE cloudformation user-api Cloudformation API service
SVCTYPE cloudwatch user-api CloudWatch API service
SVCTYPE cluster The Cluster Controller service
SVCTYPE compute user-api the Eucalyptus EC2 API service
SVCTYPE dns user-api Eucalyptus DNS server
SVCTYPE euare user-api IAM API service
SVCTYPE eucalyptus eucalyptus service implementation
SVCTYPE identity user-api Eucalyptus identity service
SVCTYPE imaging user-api Eucalyptus imaging service
SVCTYPE loadbalancing user-api ELB API service
SVCTYPE objectstorage user-api S3 API service
SVCTYPE simpleworkflow user-api Simple Workflow API service
SVCTYPE storage The Storage Controller service
SVCTYPE tokens user-api STS API service
SVCTYPE user-api The service group of all user-facing API endpoint services
SVCTYPE walrusbackend The legacy Walrus Backend service
euserv-describe-services [-a]
[--group-by-type | --group-by-zone | --group-by-host | --expert]
[--show-headers] [--show-empty-fields] [-U URL] [--region
USER@REGION] [-I KEY_ID] [-S KEY] [--security-token TOKEN]
[--filter NAME=VALUE] [--debug] [--debugger] [--version] [-h]
[SVCINSTANCE [SVCINSTANCE ...]]
| Argument | Description |
|---|---|
| SVCINSTANCE | Limit results to specific instances of services. |
| Option | Description | Required |
|---|---|---|
| -a, –all | Show all services regardless of type. | No |
| –group-by-type | Collate services by service type (default). | No |
| –group-by-zone | Collate services by availability zone. | No |
| –group-by-host | Collate services by host. | No |
| –expert | Show advanced information, including service accounts. | No |
| –show-headers | Show column headers. | No |
| –filter name=value | Restrict results to those that meet criteria. Allowed filter names: availability-zone. The service’s availability zone.host. The machine running the service.internal. Whether the service is used only internally (true or false).public. Whether the service is public (true or false).service-group. Whether the service is a member of a specific service group.service-group-member. Whether the service is a member of any service group (true or false).service-type. The type of service.state. The service’s state. | No |
Eucalyptus returns information about the services you specified.
Verify that you are looking at the cloud controllers view of the service state by explicitly running against that host:
euserv-describe-services --filter service-type=storage -U http://localhost:8773/services/Empyrean
SERVICE storage one one-sc-1 enabled
euserv-migrate-instances (-s HOST | -i INSTANCE)
[--include-dest HOST | --exclude-dest HOST]
[-U URL] [--region USER@REGION] [-I KEY_ID] [-S KEY] [--security-token
TOKEN] [--debug] [--debugger] [--version] [-h]
| Option | Description | Required |
|---|---|---|
| -s, –source host | Remove all instances from a specific host. | No |
| -i, –instance instance | Remove one instance from its current host. | No |
| –include-dest host | Allow migration to only a specific host (may be used more than once). | No |
| –exclude-dest host | Allow migration to any host except a specific one (may be used more than once). | No |
Unless requested, no output is given. You can run the euserv-describe-* command to verify that the migration activity completed successfully, as shown in the example following.
To migrate an instance from its current host:
euserv-migrate-instances -i i-8eacd211
euserv-describe-node-controllers
NODE zone-555 10.104.1.200 enabled
NODE zone-555 10.104.1.201 enabled
INSTANCE i-8eacd211
euserv-modify-service -s STATE [-U URL] [--region USER@REGION]
[-I KEY_ID] [-S KEY] [--security-token TOKEN]
[--debug] [--debugger] [--version] [-h] SVCINSTANCE
| Argument | Description |
|---|---|
| SVCINSTANCE | The name of the service instance to modify. |
| Option | Description | Required |
|---|---|---|
| -s, –state state | The state to change to. | Yes |
No output is given. You can run the euserv-describe-services command to verify that the modification completed successfully, as shown in the example following.
To modify the state of a storage controller service named “two-sc-1” to stopped:
euserv-modify-service -s stopped two-sc-1
euserv-describe-services two-sc-1
SERVICE storage two two-sc-1 stopped
euserv-register-service -t TYPE -h IP [--port PORT] [-z ZONE] [-U URL]
[--region USER@REGION] [-I KEY_ID] [-S KEY]
[--security-token TOKEN] [--debug] [--debugger] [--version]
[--help] SVCINSTANCE
| Argument | Description |
|---|---|
| SVCINSTANCE | The name of the new service instance to register. |
| Option | Description | Required |
|---|---|---|
| -t, –type type | The new service instance’s type. | Yes |
| -h, –host IP | The host on which the new instance of the service runs. | Yes |
| –port port | The port on which the new instance of the service runs (default for cluster: 8774, otherwise: 8773). | No |
| -z, –availability-zone zone | The availability zone in which to register the new service instance. This is required only for services of certain types. | Conditional |
No output is given when it succeeds.
To register the ufs service named “user-api-5”:
euserv-register-service -t user-api -h 10.0.0.15 user-api-5
Eucalyptus exposes a number of variables that can be configured using the command. This topic explains what types of variables Eucalyptus uses, and lists the most common configurable variables.
Eucalyptus uses two types of variables: ones that can be changed (as configuration options), and ones that cannot be changed (they are displayed as variables, but configured by modifying the eucalyptus.conf file on the CC).
The following table contains a list of common Eucalyptus cloud variables.
| Variable | Description |
|---|---|
| authentication.access_keys_limit | Limit for access keys per user |
| authentication.authorization_cache | Authorization cache configuration, for credentials and authorization metadata |
| authentication.authorization_expiry | Default expiry for cached authorization metadata |
| authentication.authorization_reuse_expiry | Default expiry for re-use of cached authorization metadata on failure |
| authentication.credential_download_generate_certificate | Strategy for generation of certificates on credential download (Never |
| authentication.credential_download_host_match | CIDR to match against for host address selection |
| authentication.credential_download_port | Port to use in service URLs when ‘bootstrap.webservices.port’ is not appropriate. |
| authentication.default_password_expiry | Default password expiry time |
| authentication.max_policy_attachments | Maximum number of attached managed policies |
| authentication.max_policy_size | Maximum size for an IAM policy (bytes) |
| authentication.signing_certificates_limit | Limit for signing certificates per user |
| authentication.system_account_quota_enabled | Process quotas for system accounts |
| autoscaling.activityexpiry | Expiry age for scaling activities. Older activities are deleted. |
| autoscaling.activityinitialbackoff | Initial back-off period for failing activities. |
| autoscaling.activitymaxbackoff | Maximum back-off period for failing activities. |
| autoscaling.activitytimeout | Timeout for a scaling activity. |
| autoscaling.maxlaunchincrement | Maximum instances to launch at one time. |
| autoscaling.maxregistrationretries | Number of times to attempt load balancer registration for each instance. |
| autoscaling.maxtags | Maximum number of user defined tags for a group |
| autoscaling.pendinginstancetimeout | Timeout for a pending instance. |
| autoscaling.suspendedprocesses | Globally suspend scaling processes; a comma-delimited list of processes (Launch,Terminate,HealthCheck, ReplaceUnhealthy,AZRebalance, AlarmNotification,ScheduledActions, AddToLoadBalancer). Default is empty, meaning the processes are not suspended. |
| autoscaling.suspendedtasks | Suspended scaling tasks. |
| autoscaling.suspensionlaunchattemptsthreshold | Minimum launch attempts for administrative suspension of scaling activities for a group. |
| autoscaling.suspensiontimeout | Timeout for administrative suspension of scaling activities for a group. |
| autoscaling.untrackedinstancetimeout | Timeout for termination of untracked auto scaling instances. |
| autoscaling.zonefailurethreshold | Time after which an unavailable zone should be treated as failed |
| bootstrap.async.future_listener_debug_limit_secs | Number of seconds a future listener can execute before a debug message is logged. |
| bootstrap.async.future_listener_error_limit_secs | Number of seconds a future listener can execute before an error message is logged. |
| bootstrap.async.future_listener_get_retries | Total number of seconds a future listener’s executor waits to get(). |
| bootstrap.async.future_listener_get_timeout | Number of seconds a future listener’s executor waits to get() per call. |
| bootstrap.async.future_listener_info_limit_secs | Number of seconds a future listener can execute before an info message is logged. |
| bootstrap.hosts.state_initialize_timeout | Timeout for state initialization (in msec). |
| bootstrap.hosts.state_transfer_timeout | Timeout for state transfers (in msec). |
| bootstrap.notifications.batch_delay_seconds | Interval (in seconds) during which a notification will be delayed to allow for batching events for delivery. |
| bootstrap.notifications.digest | Send a system state digest periodically. |
| bootstrap.notifications.digest_frequency_hours | Period (in hours) with which a system state digest will be delivered. |
| bootstrap.notifications.digest_only_on_errors | If sending system state digests is set to true, then only send the digest when the system has failures to report. |
| bootstrap.notifications.digest_frequency_hours | Period (in hours) with which a system state digest will be delivered. |
| bootstrap.notifications.digest_only_on_errors | If sending system state digests is set to true, then only send the digest when the system has failures to report. |
| bootstrap.notifications.email_from | From email address used for notification delivery. |
| bootstrap.notifications.email_from_name | From email name used for notification delivery. |
| bootstrap.notifications.email_from_name | From email name used for notification delivery. |
| bootstrap.notifications.email_subject_prefix | Email subject used for notification delivery. |
| bootstrap.notifications.email_to | Email address where notifications are to be delivered. |
| bootstrap.notifications.include_fault_stack | Period (in hours) with which a system state digest will be delivered. |
| bootstrap.notifications.email.email_smtp_host | SMTP host to use when sending email. If unset, the following values are tried: 1) the value of the ‘mail.smtp.host’ system variable, 2) localhost, 3) mailhost. |
| bootstrap.notifications.email.email_smtp_port | SMTP port to use when sending email. Defaults to 25 |
| bootstrap.servicebus.common_thread_pool_size | Default thread pool for component message processing. When the size of the common thread pool is zero or less, Eucalyptus uses separate thread pools for each component and a pool for dispatching. Default size = 256 threads. |
| bootstrap.servicebus.component_thread_pool_size | Used when the size of the common thread pool is zero or less. Default size = 64 threads. |
| bootstrap.servicebus.context_message_log_whitelist | Message patterns to match for logging. Allows selective message logging at INFO level. A list of wildcards that allows selective logging for development or troubleshooting (e.g., on request/response, on a package, on a component). Logging can impact security; do not use as a general purpose logging feature. |
| bootstrap.servicebus.context_timeout | Message context timeout in seconds. Default = 60 seconds. |
| bootstrap.servicebus.dispatch_thread_pool_size | Used when the size of the common thread pool is zero or less. Default size = 256 threads. |
| bootstrap.servicebus.hup | Do a soft reset. Default = 0 (false). |
| bootstrap.timer.rate | Amount of time (in milliseconds) before a previously running instance which is not reported will be marked as terminated. |
| bootstrap.topology.coordinator_check_backoff_secs | Backoff between service state checks (in seconds). |
| bootstrap.topology.local_check_backoff_secs | Backoff between service state checks (in seconds). |
| bootstrap.tx.concurrent_update_retries | Maximum number of times a transaction may be retried before giving up. |
| bootstrap.webservices.async_internal_operations | Execute internal service operations from a separate thread pool (with respect to I/O). |
| bootstrap.webservices.async_operations | Execute service operations from a separate thread pool (with respect to I/O). |
| bootstrap.webservices.async_pipeline | Execute service specific pipeline handlers from a separate thread pool (with respect to I/O). |
| bootstrap.webservices.channel_connect_timeout | Channel connect timeout (ms). |
| bootstrap.webservices.channel_keep_alive | Socket keep alive. |
| bootstrap.webservices.channel_nodelay | Server socket TCP_NODELAY. |
| bootstrap.webservices.channel_reuse_address | Socket reuse address. |
| bootstrap.webservices.client_http_chunk_buffer_max | Server http chunk max. |
| bootstrap.webservices.client_http_pool_acquire_timeout | Client http pool acquire timeout |
| bootstrap.webservices.client_internal_connect_timeout_millis | Client connection timeout (ms) |
| bootstrap.webservices.client_internal_hmac_signature_enabled | Client HMAC signature version 4 enabled |
| bootstrap.webservices.client_internal_timeout_secs | Client idle timeout (secs). |
| bootstrap.webservices.client_message_log_whitelist | Client message patterns to match for logging |
| bootstrap.webservices.client_pool_max_threads | Server worker thread pool max. |
| bootstrap.webservices.clock_skew_sec | A max clock skew value (in seconds) between client and server accepted when validating timestamps in Query/REST protocol. |
| bootstrap.webservices.cluster_connect_timeout_millis | Cluster connect timeout (ms). |
| bootstrap.webservices.default_aws_sns_uri_scheme | Default scheme for AWS_SNS_URL. |
| bootstrap.webservices.default_ec2_uri_scheme | Default scheme for EC2_URL. |
| bootstrap.webservices.default_euare_uri_scheme | Default scheme for EUARE_URL. |
| bootstrap.webservices.default_https_enabled | Default scheme prefix. |
| bootstrap.webservices.default_s3_uri_scheme | Default scheme for S3_URL. |
| bootstrap.webservices.disabled_soap_api_components | List of services with disabled SOAP APIs. |
| bootstrap.webservices.http_max_chunk_bytes | Maximum HTTP chunk size (bytes). |
| bootstrap.webservices.http_max_header_bytes | Maximum HTTP headers size (bytes). |
| bootstrap.webservices.http_max_initial_line_bytes | Maximum HTTP initial line size (bytes). |
| bootstrap.webservices.http_max_requests_per_connection | Maximum HTTP requests per persistent connection |
| bootstrap.webservices.http_server_header | HTTP server header returned for responses. If set to “default”, the standard version header is returned, e.g. Eucalyptus/4.3.1. If set to another value, that value is returned in the header, except for an empty value, which results in no server header being returned.Default: default |
| bootstrap.webservices.listener_address_match | CIDRs matching addresses to bind on Default interface is always bound regardless. |
| bootstrap.webservices.log_requests | Enable request logging. |
| bootstrap.webservices.oob_internal_operations | Execute internal service operations out of band from the normal service bus. |
| bootstrap.webservices.pipeline_enable_query_decompress | Enable Query Pipeline http request decompression |
| bootstrap.webservices.pipeline_idle_timeout_seconds | Server socket idle time-out. |
| bootstrap.webservices.pipeline_max_query_request_size | Maximum Query Pipeline http chunk size (bytes). |
| bootstrap.webservices.port | Port to bind Port 8773 is always bound regardless. |
| bootstrap.webservices.replay_skew_window_sec | Time interval duration (in seconds) during which duplicate signatures will be accepted to accommodate collisions. |
| bootstrap.webservices.server_boss_pool_max_mem_per_conn | Server max selector memory per connection. |
| bootstrap.webservices.server_boss_pool_max_threads | Server selector thread pool max. |
| bootstrap.webservices.server_boss_pool_timeout_millis | Service socket select timeout (ms). |
| bootstrap.webservices.server_boss_pool_total_mem | Server worker thread pool max. |
| bootstrap.webservices.server_channel_nodelay | Server socket TCP_NODELAY. |
| bootstrap.webservices.server_channel_reuse_address | Server socket reuse address. |
| bootstrap.webservices.server_pool_max_mem_per_conn | Server max worker memory per connection. |
| bootstrap.webservices.server_pool_max_threads | Server worker thread pool max. |
| bootstrap.webservices.server_pool_timeout_millis | Service socket select timeout (ms). |
| bootstrap.webservices.server_pool_total_mem | Server max worker memory total. |
| bootstrap.webservices.statistics | Record and report service times. |
| bootstrap.webservices.unknown_parameter_handling | Request unknown parameter handling (default |
| bootstrap.webservices.use_dns_delegation | Use DNS delegation. |
| bootstrap.webservices.use_instance_dns | Use DNS names for instances. |
| bootstrap.webservices.ssl.client_https_enabled | Client HTTPS enabled |
| bootstrap.webservices.ssl.client_https_server_cert_verify | Client HTTPS verify server certificate enabled |
| bootstrap.webservices.ssl.client_ssl_ciphers | Client HTTPS ciphers for internal use |
| bootstrap.webservices.ssl.client_ssl_protocols | Client HTTPS protocols for internal use |
| bootstrap.webservices.ssl.server_alias | Alias of the certificate entry in euca.p12 to use for SSL for webservices. |
| bootstrap.webservices.ssl.server_password | Password of the private key corresponding to the specified certificate for SSL for web services. |
| bootstrap.webservices.ssl.server_ssl_ciphers | SSL ciphers for web services. |
| bootstrap.webservices.ssl.server_ssl_protocols | SSL protocols for web services. |
| bootstrap.webservices.ssl.user_ssl_ciphers | SSL ciphers for external use. |
| bootstrap.webservices.ssl.user_ssl_default_cas | Use default CAs with SSL for external use. |
| bootstrap.webservices.ssl.user_ssl_enable_hostname_verification | SSL hostname validation for external use. |
| bootstrap.webservices.ssl.user_ssl_protocols | SSL protocols for external use. |
| cloud.db_check_poll_time | Poll time (ms) for db connection check |
| cloud.db_check_threshold | Threshold (number of connections or %) for db connection check |
| cloud.euca_log_level | Log level for dynamic override. |
| cloud.identifier_canonicalizer | Name of the canonicalizer for resource identifiers. |
| cloud.log_file_disk_check_poll_time | Poll time (ms) for log file disk check |
| cloud.log_file_disk_check_threshold | Threshold (bytes or %) for log file disk check |
| cloud.memory_check_poll_time | Poll time (ms) for memory check |
| cloud.memory_check_ratio | Ratio (of post-garbage collected old-gen memory) for memory check |
| cloud.trigger_fault | Fault id last used to trigger test |
| cloud.cluster.disabledinterval | The time period between service state checks for a Cluster Controller which is DISABLED. |
| cloud.cluster.enabledinterval | The time period between service state checks for a Cluster Controller which is ENABLED. |
| cloud.cluster.notreadyinterval | The time period between service state checks for a Cluster Controller which is NOTREADY. |
| cloud.cluster.pendinginterval | The time period between service state checks for a Cluster Controller which is PENDING. |
| cloud.cluster.requestworkers | The number of concurrent requests which will be sent to a single Cluster Controller. |
| cloud.cluster.startupsyncretries | The number of times a request will be retried while bootstrapping a Cluster Controller. |
| cloud.images.cleanupperiod | The period between runs for clean up of deregistered images. |
| cloud.images.defaultvisibility | The default value used to determine whether or not images are marked ‘public’ when first registered. |
| cloud.images.maximagesizegb | The maximum registerable image size in GB |
| cloud.images.maxmanifestsizebytes | The maximum allowed image manifest size in bytes |
| cloud.long_identifier_prefixes | List of resource identifier prefixes for long identifiers or * for all |
| cloud.monitor.default_poll_interval_mins | How often the CLC requests data from the CC. Default value is 5 minutes. |
| cloud.monitor.history_size | How many data value samples are sent from the CC to the CLC. The default value is 5. |
| cloud.network.address_pending_timeout | Minutes before a pending system public address allocation times out and is released. Default: 35 minutes. |
| cloud.network.ec2_classic_additional_protocols_allowed | Comma delimited list of protocol numbers supported in EDGE mode for security group rules beyond the EC2-Classic defaults (TCP,UDP,ICMP). Only valid IANA protocol numbers are accepted. Default: None |
| cloud.network.max_broadcast_apply | Maximum time to apply network information. Default: 120 seconds. |
| cloud.network.min_broadcast_interval | Minimum interval between broadcasts of network information. Default: 5 seconds. |
| cloud.network.network_index_pending_timeout | Minutes before a pending index allocation times out and is released. Default: 35 minutes. |
| cloud.short_identifier_prefixes | List of resource identifier prefixes for short identifiers or * for all |
| cloud.vmstate.buried_time | Amount of time (in minutes) to retain unreported terminated instance data. |
| cloud.vmstate.ebs_root_device_name | Name for root block device mapping |
| cloud.vmstate.ebs_volume_creation_timeout | Amount of time (in minutes) before a EBS volume backing the instance is created |
| cloud.vmstate.instance_private_prefix | Private name prefix for instance DNS |
| cloud.vmstate.instance_public_prefix | Public name prefix for instance DNS |
| cloud.vmstate.instance_reachability_timeout | Amount of time (in minutes) before a VM which is not reported by a cluster will fail a reachability test. |
| cloud.vmstate.instance_subdomain | Subdomain to use for instance DNS. |
| cloud.vmstate.instance_timeout | Amount of time (default unit minutes) before a previously running instance which is not reported will be marked as terminated. |
| cloud.vmstate.instance_touch_interval | Amount of time (in minutes) between updates for a running instance. |
| cloud.vmstate.mac_prefix | Default prefix to use for instance / network interface MAC addresses. |
| cloud.vmstate.max_state_threads | Maximum number of threads the system will use to service blocking state changes. |
| cloud.vmstate.migration_refresh_time | Maximum amount of time (in seconds) that migration state will take to propagate state changes (e.g., to tags). |
| cloud.vmstate.pending_time | Amount of time (in minutes) before a pending instance will be terminated. |
| cloud.vmstate.shut_down_time | Amount of time (in minutes) before a VM which is not reported by a cluster will be marked as terminated. |
| cloud.vmstate.stopping_time | Amount of time (in minutes) before a stopping VM which is not reported by a cluster will be marked as terminated. |
| cloud.vmstate.terminated_time | Amount of time (in minutes) that a terminated VM will continue to be reported. |
| cloud.vmstate.tx_retries | Number of times to retry transactions in the face of potential concurrent update conflicts. |
| cloud.vmstate.unknown_instance_handlers | Comma separated list of handlers to use for unknown instances (‘restore’, ‘restore-failed’, ’terminate’, ’terminate-done’) |
| cloud.vmstate.user_data_max_size_kb | Max length (in KB) that the user data file can be for an instance (after base 64 decoding) |
| cloud.vmstate.vm_initial_report_timeout | Amount of time (in seconds) since completion of the creating run instance operation that the new instance is treated as unreported if not… reported. |
| cloud.vmstate.vm_metadata_generated_cache | Instance metadata generated data cache configuration. The cache is used for IAM metadata (../latest/meta-data/iam/) and instance identity (../latest/dynamic/instance-identity/).Default: maximumSize=1000, expireAfterWrite=5m |
| cloud.vmstate.vm_metadata_instance_cache | Instance metadata cache configuration. |
| cloud.vmstate.vm_metadata_request_cache | Instance metadata instance resolution cache configuration. |
| cloud.vmstate.vm_metadata_user_data_cache | Instance metadata user data cache configuration. |
| cloud.vmstate.vm_state_settle_time | Amount of time (in seconds) to let instance state settle after a transition to either stopping or shutting-down. |
| cloud.vmstate.volatile_state_interval_sec | Period (in seconds) between state updates for actively changing state. |
| cloud.vmstate.volatile_state_timeout_sec | Timeout (in seconds) before a requested instance terminate will be repeated. |
| cloud.vmtypes.default_type_name | Default type used when no instance type is specified for run instances. |
| cloud.vmtypes.format_ephemeral_storage | Format first ephemeral disk by defaut with ext3 |
| cloud.vmtypes.merge_ephemeral_storage | Merge non-root ephemeral disks |
| cloud.volumes.deleted_time | Amount of time (in minutes) that a deleted volume will continue to be reported |
| cloud.vpc.defaultvpc | Enable default VPC. |
| cloud.vpc.defaultvpccidr | CIDR to use when creating default VPCs |
| cloud.vpc.networkaclspervpc | Maximum number of network ACLs for each VPC. |
| cloud.vpc.reservedcidrs | Comma separated list of reserved CIDRs |
| cloud.vpc.routespertable | Maximum number of routes for each route table. |
| cloud.vpc.routetablespervpc | Maximum number of route tables for each VPC. |
| cloud.vpc.rulespernetworkacl | Maximum number of rules per direction for each network ACL. |
| cloud.vpc.rulespersecuritygroup | Maximum number of associated security groups for each network interface . |
| cloud.vpc.securitygroupspernetworkinterface | Maximum number of associated security groups for each network interface . |
| cloud.vpc.securitygroupspervpc | Maximum number of security groups for each VPC. |
| cloud.vpc.subnetspervpc | Maximum number of subnets for each VPC. |
| cloudformation.autoscaling_group_deleted_max_delete_retry_secs | The amount of time (in seconds) to wait for an autoscaling group to be deleted after deletion) |
| cloudformation.autoscaling_group_zero_instances_max_delete_retry_secs | The amount of time (in seconds) to wait for an autoscaling group to have zero instances during delete |
| cloudformation.cfn_instance_auth_cache | CloudFormation instance credential authentication cache |
| cloudformation.instance_attach_volume_max_create_retry_secs | The amount of time (in seconds) to wait for an instance to have volumes attached after creation) |
| cloudformation.instance_running_max_create_retry_secs | The amount of time (in seconds) to wait for an instance to be running after creation) |
| cloudformation.instance_terminated_max_delete_retry_secs | The amount of time (in seconds) to wait for an instance to be terminated after deletion) |
| cloudformation.max_attributes_per_mapping | The maximum number of attributes allowed in a mapping in a template |
| cloudformation.max_mappings_per_template | The maximum number of mappings allowed in a template |
| cloudformation.max_outputs_per_template | The maximum number of outputs allowed in a template |
| cloudformation.max_parameters_per_template | The maximum number of outputs allowed in a template |
| cloudformation.max_resources_per_template | The maximum number of resources allowed in a template |
| cloudformation.nat_gateway_available_max_create_retry_secs | The amount of time (in seconds) to wait for a nat gateway to be available after create) |
| cloudformation.network_interface_attachment_max_create_or_update_retry_secs | The amount of time (in seconds) to wait for a network interface to be attached during create or update) |
| cloudformation.network_interface_available_max_create_retry_secs | The amount of time (in seconds) to wait for a network interface to be available after create) |
| cloudformation.network_interface_deleted_max_delete_retry_secs | The amount of time (in seconds) to wait for a network interface to be deleted) |
| cloudformation.network_interface_detachment_max_delete_or_update_retry_secs | The amount of time (in seconds) to wait for a network interface to detach during delete or update) |
| cloudformation.pseudo_param_partition | CloudFormation AWS::Partition (default: eucalyptus) |
| cloudformation.pseudo_param_urlsuffix | CloudFormation AWS::URLSuffix (default: dns domain) |
| cloudformation.region | The value of AWS::Region and value in CloudFormation ARNs for Region |
| cloudformation.request_template_body_max_length_bytes | The maximum number of bytes in a request-embedded template |
| cloudformation.request_template_url_max_content_length_bytes | The maximum number of bytes in a template referenced via a URL |
| cloudformation.security_group_max_delete_retry_secs | The amount of time (in seconds) to retry security group deletes (may fail if instances from autoscaling group) |
| cloudformation.subnet_max_delete_retry_secs | The amount of time (in seconds) to retry subnet deletes |
| cloudformation.swf_activity_worker_config | JSON configuration for the cloudformation simple workflow activity worker |
| cloudformation.swf_domain | The simple workflow service domain for cloudformation |
| cloudformation.swf_tasklist | The simple workflow service task list for cloudformation |
| cloudformation.url_domain_whitelist | A comma separated white list of domains (other than Eucalyptus S3 URLs) allowed by CloudFormation URL parameters |
| cloudformation.volume_attachment_max_create_retry_secs | The amount of time (in seconds) to wait for a volume to be attached during create) |
| cloudformation.volume_available_max_create_retry_secs | The amount of time (in seconds) to wait for a volume to be available after create) |
| cloudformation.volume_deleted_max_delete_retry_secs | The amount of time (in seconds) to wait for a volume to be deleted) |
| cloudformation.volume_detachment_max_delete_retry_secs | The amount of time (in seconds) to wait for a volume to detach during delete) |
| cloudformation.volume_snapshot_complete_max_delete_retry_secs | The amount of time (in seconds) to wait for a snapshot to be complete (if specified as the deletion policy) before a volume is deleted) |
| cloudformation.wait_condition_bucket_prefix | The prefix of the bucket used for wait condition handles |
| cloudwatch.disable_cloudwatch_service | Set this to true to stop cloud watch alarm evaluation and new alarm/metric data entry |
| dns.dns_listener_address_match | Additional address patterns to listen on for DNS requests. |
| dns.enabled | Enable pluggable DNS resolvers. This must be ’true’ for any pluggable resolver to work. Also, each resolver may need to be separately enabled. |
| dns.search | Comma separated list of domains to search, OS settings used if none specified (a change requires restart). |
| dns.server | Comma separated list of name servers; OS settings used if none specified (change requires restart) |
| dns.server_pool_max_threads | Server worker thread pool max. |
| dns.server_pool_max_threads | Server worker thread pool max. |
| dns.instancedata.enabled | Enable the instance-data resolver. dns.enabled must also be ’true’. |
| dns.negative_ttl | Time-to-live for negative caching on authoritative records. Since version 5.1. |
| dns.ns.enabled | Enable the NS resolver. dns.enabled must also be ’true’. |
| dns.recursive.enabled | Enable the recursive DNS resolver. dns.enabled must also be ’true’. |
| dns.services.enabled | Enable the service topology resolver. dns.enabled must also be ’true’. |
| dns.split_horizon.enabled | Enable the split-horizon DNS resolution for internal instance public DNS name queries. dns.enabled must also be ’true'. |
| dns.spoof_regions.enabled | Enable the spoofing resolver which allows for AWS DNS name emulation for instances. |
| dns.spoof_regions.region_name | Internal region name. If set, the region name to expect as the second label in the DNS name. For example, to treat your Eucalyptus install like a region named ’eucalyptus’, set this value to eucalyptus. Then, e.g., autoscaling.eucalyptus.amazonaws.com will resolve to the service address when using this DNS server. The specified name creates a pseudo-region with DNS names like ec2.pseudo-region.amazonaws.com will resolve to Eucalyptus endpoints from inside of instances. Here ec2 is any service name supported by Eucalyptus. Those that are not supported will continue to resolve through AWS’s DNS. |
| dns.spoof_regions.spoof_aws_default_regions | Enable spoofing of the default AWS DNS names, e.g., ec2.amazonaws.com would resolve to the ENABLED Cloud Controller. Here ec2 is any service name supported by Eucalyptus. Those that are not supported will continue to resolve through AWS’s DNS. |
| dns.spoof_regions.spoof_aws_regions | Enable spoofing for the normal AWS regions, e.g., ec2.us-east-1.amazonaws.com would resolve to the ENABLED Cloud Controller. Here ec2 is any service name supported by Eucalyptus. Those that are not supported will continue to resolve through AWS’s DNS. |
| dns.tcp.timeout_seconds | Variable controlling tcp handler timeout in seconds. |
| dns.ttl | Default time-to-live for authoritative records. Since version 5.1. |
| dns.dns_listener_port | Port number to listen on for DNS requests |
| objectstorage.bucket_creation_wait_interval_seconds | Interval, in seconds, during which buckets in creating-state are valid. After this interval, the operation is assumed failed. |
| objectstorage.bucket_naming_restrictions | The S3 bucket naming restrictions to enforce. Values are ‘dns-compliant’ or ’extended’. Default is ’extended’. dns_compliant is non-US region S3 names, extended is for US-Standard Region naming. See http://docs.aws.amazon.com/AmazonS3/latest/dev/BucketRestrictions.html.[]() |
| objectstorage.bucket_reserved_cnames | List of host names that may not be used as bucket cnames |
| objectstorage.cleanup_task_interval_seconds | Interval, in seconds, at which cleanup tasks are initiated for removing old/stale objects. |
| objectstorage.dogetputoncopyfail | Should provider client attempt a GET / PUT when backend does not support Copy operation |
| objectstorage.failed_put_timeout_hrs | Number of hours to wait for object PUT operations to be allowed to complete before cleanup. |
| objectstorage.max_buckets_per_account | Maximum number of buckets per account |
| objectstorage.max_tags | Maximum number of user defined tags for a bucket |
| objectstorage.max_total_reporting_capacity_gb | Total ObjectStorage storage capacity for Objects solely for reporting usage percentage. Not a size restriction. No enforcement of this value |
| objectstorage.providerclient | Object Storage Provider client to use for backend |
| objectstorage.queue_size | Channel buffer queue size for uploads |
| objectstorage.queue_timeout | Channel buffer queue timeout (in seconds) |
| objectstorage.s3client.buffer_size | Internal S3 client buffer size |
| objectstorage.s3client.connection_timeout_ms | Internal S3 client connection timeout in ms |
| objectstorage.s3client.max_connections | Internal S3 client maximum connections |
| objectstorage.s3client.max_error_retries | Internal S3 client maximum retries on error |
| objectstorage.s3client.socket_read_timeout_ms | Internal S3 client socket read timeout in ms |
| objectstorage.s3provider.s3accesskey | Local Store S3 Access Key. |
| objectstorage.s3provider.s3endpoint | External S3 endpoint. |
| objectstorage.s3provider.s3secretkey | Local Store S3 Secret Key. |
| objectstorage.s3provider.s3usebackenddns | Use DNS virtual-hosted-style bucket names for communication to service backend. |
| objectstorage.s3provider.s3usehttps | Use HTTPS for communication to service backend. |
| region.region_enable_ssl | Enable SSL (HTTPS) for regions. |
| region.region_name | Region name. |
| region.region_ssl_ciphers | Ciphers to use for region SSL |
| region.region_ssl_default_cas | Use default CAs for region SSL connections. |
| region.region_ssl_protocols | Protocols to use for region SSL |
| region.region_ssl_verify_hostnames | Verify hostnames for region SSL connections. |
| services.imaging.import_task_expiration_hours | expiration hours of import volume/instance tasks |
| services.imaging.import_task_timeout_minutes | expiration time in minutes of import tasks |
| services.imaging.worker.availability_zones | availability zones for imaging worker |
| services.imaging.worker.configured | Prepare imaging service so a worker can be launched. If something goes south with the service there is a big chance that setting it to false and back to true would solve issues. |
| services.imaging.worker.expiration_days | the days after which imaging work VMs expire |
| services.imaging.worker.healthcheck | enabling imaging worker health check |
| services.imaging.worker.image | EMI containing imaging worker |
| services.imaging.worker.init_script | bash script that will be executed before service configuration and start up |
| services.imaging.worker.instance_type | instance type for imaging worker |
| services.imaging.worker.keyname | keyname to use when debugging imaging worker |
| services.imaging.worker.log_server | address/ip of the server that collects logs from imaging wokrers |
| services.imaging.worker.log_server_port | UDP port that log server is listening to |
| services.imaging.worker.log_server_port | UDP port that log server is listening to |
| services.imaging.worker.ntp_server | address of the NTP server used by imaging worker |
| services.loadbalancing.dns_resolver_enabled | Enable the load balancing DNS resolver. dns.enabled must also be ’true’. |
| services.loadbalancing.dns_subdomain | loadbalancer dns subdomain |
| services.loadbalancing.dns_ttl | loadbalancer dns ttl value |
| services.loadbalancing.max_tags | Maximum number of user defined tags for a load balancer |
| services.loadbalancing.restricted_ports | The ports restricted for use as a loadbalancer port. Format should be port(, port) or port-port |
| services.loadbalancing.vm_per_zone | number of VMs per loadbalancer zone |
| services.loadbalancing.vpc_cidrs | Comma separated list of CIDRs for use with ELB VPCs |
| services.loadbalancing.worker.app_cookie_duration | duration of app-controlled cookie to be kept in-memory (hours) |
| services.loadbalancing.worker.expiration_days | the days after which the loadbalancer VMs expire |
| services.loadbalancing.worker.image | EMI containing haproxy and the controller |
| services.loadbalancing.worker.init_script | bash script that will be executed before service configuration and start up |
| services.loadbalancing.worker.instance_type | instance type for loadbalancer instances |
| services.loadbalancing.worker.keyname | keyname to use when debugging loadbalancer VMs |
| services.loadbalancing.worker.ntp_server | the address of the NTP server used by loadbalancer VMs |
| services.simpleworkflow.activitytypesperdomain | Maximum number of activity types for each domain. |
| services.simpleworkflow.deprecatedactivitytyperetentionduration | Deprecated activity type retention time. |
| services.simpleworkflow.deprecateddomainretentionduration | Deprecated domain minimum retention time. |
| services.simpleworkflow.deprecatedworkflowtyperetentionduration | Deprecated workflow type minimum retention time. |
| services.simpleworkflow.openactivitytasksperworkflowexecution | Maximum number of open activity tasks for each workflow execution. |
| services.simpleworkflow.opentimersperworkflowexecution | Maximum number of open timers for each workflow execution. |
| services.simpleworkflow.openworkflowexecutionsperdomain | Maximum number of open workflow executions for each domain. |
| services.simpleworkflow.systemonly | Service available for internal/administrator use only. |
| services.simpleworkflow.workflowexecutionduration | Maximum workflow execution time. |
| services.simpleworkflow.workflowexecutionhistorysize | Maximum number of events per workflow execution. |
| services.simpleworkflow.workflowexecutionretentionduration | Maximum workflow execution history retention time. |
| services.simpleworkflow.workflowtypesperdomain | Maximum number of workflow types for each domain. |
| stats.config_update_check_interval_seconds | Interval, in seconds, at which the sensor configuration is checked for changes |
| stats.enable_stats | Enable Eucalyptus internal monitoring stats |
| stats.event_emitter | Internal stats emitter FQ classname used to send metrics to monitoring system |
| stats.file_system_emitter.stats_data_permissions | group permissions to place on stats data files in string form. eg. rwxr-x–x |
| stats.file_system_emitter.stats_group_name | group name that owns stats data files |
| storage.global_total_snapshot_size_limit_gb | Maximum total snapshot capacity (GB) |
| system.dns.dnsdomain | Domain name to use for DNS. |
| system.dns.nameserver | Nameserver hostname. |
| system.dns.nameserveraddress | Nameserver IP address. |
| system.dns.nameserveraddress | Nameserver IP address. |
| system.dns.registrationid | Unique ID of this cloud installation. |
| system.exec.io_chunk_size | Size of IO chunks for streaming IO |
| system.exec.max_restricted_concurrent_ops | Maximum number of concurrent processes which match any of the patterns in system.exec.restricted_concurrent_ops. |
| system.exec.restricted_concurrent_ops | Comma-separated list of commands which are restricted by system.exec.max_restricted_concurrent_ops. |
| tagging.max_tags_per_resource | The maximum number of tags per resource for each account |
| tokens.disabledactions | Actions to disable |
| tokens.enabledactions | Actions to enable (ignored if empty) |
| tokens.rolearnaliaswhitelist | Permitted account aliases for role Amazon Resource Names (ARNs). Value is a list, for example: eucalyptus,aws,dev*,prod* in the case where multiple aliases are permitted. Default: eucalyptus |
| tokens.webidentityoidcdiscoverycache | Cache settings for discovered OpenID Connect metadata: provider configuration and keys. Works with tokens.webidentityoidcdiscoveryrefresh. Default: maximumSize=20, expireAfterWrite=15m |
| tokens.webidentityoidcdiscoveryrefresh | OpenID Connect discovery cache refresh expiry. Controls the time in seconds between checks for updated OIDC metadata. Works with tokens.webidentityoidcdiscoverycache. Default: 60 |
| tokens.webidentitysignaturealgorithmwhitelist | List of JSON Web Signature algorithms to allow in web identity tokens. The algorithm whitelist can be used to permit use of these signature algorithms: RS256, RS384, RS512, PS256, PS384, PS512. Default: RS512 |
| tokens.webidentitytokenskew | A clock skew value in seconds. The Web identity token expiry / not before validation is allowed within the configured skew. Default: 60 |
| walrusbackend.storagedir | Path to buckets storage |
| ZONE.storage.blockstoragemanager | EBS Block Storage Manager to use for backend |
| ZONE.storage.cephconfigfile | Absolute path to Ceph configuration (ceph.conf) file. Default value is ‘/etc/ceph/ceph.conf’ |
| ZONE.storage.cephkeyringfile | Absolute path to Ceph keyring (ceph.client.eucalyptus.keyring) file. Default value is ‘/etc/ceph/ceph.client.eucalyptus.keyring’ |
| ZONE.storage.cephsnapshotpools | Ceph storage pool(s) made available to Eucalyptus for EBS snapshots. Use a comma separated list for configuring multiple pools. Default value is ‘rbd’ |
| ZONE.storage.cephuser | Ceph username employed by Eucalyptus operations. Default value is ’eucalyptus' |
| ZONE.storage.cephvolumepools | Ceph storage pool(s) made available to Eucalyptus for EBS volumes. Use a comma separated list for configuring multiple pools. Default value is ‘rbd’ |
| ZONE.storage.chapuser | User ID for CHAP authentication |
| ZONE.storage.dasdevice | Direct attached storage device location |
| ZONE.storage.maxconcurrentsnapshots | Maximum number of snapshots processed on the block storage backend at a given time |
| ZONE.storage.maxconcurrentsnapshottransfers | Maximum number of snapshots that can be uploaded to or downloaded from objectstorage gateway at a given time |
| ZONE.storage.maxconcurrentvolumes | Maximum number of volumes processed on the block storage backend at a given time |
| ZONE.storage.maxsnapshotdeltas | A non-zero integer value enables upload of incremental snapshots when possible. The configured value indicates the SC to create/upload that many snapshot deltas for a given EBS volume before triggering a full upload of the snapshot contents. Between any two consecutive full snapshot uploads for a given EBS volume, there will be at most maxsnapshotdeltas number of incremental snapshot uploads. A value of 0 indicates that a newly created snapshot will always be uploaded in its entirety (that is, no deltas). Snapshot deltas are only used when your backend is Ceph-RBD. ZONE.storage.shouldtransfersnapshots must be set to true to enable snapshot deltas.Default: 0 |
| ZONE.storage.maxsnapshotpartsqueuesize | Maximum number of snapshot parts per snapshot that can be spooled on the disk |
| ZONE.storage.maxtotalvolumesizeingb | Total disk space reserved for volumes |
| ZONE.storage.maxvolumesizeingb | Max volume size |
| ZONE.storage.ncpaths | iSCSI Paths for NC. Default value is ’nopath' |
| ZONE.storage.readbuffersizeinmb | Buffer size in MB for reading data from snapshot when uploading snapshot to objectstorage gateway |
| ZONE.storage.resourceprefix | Prefix for resource name on SAN |
| ZONE.storage.resourcesuffix | Suffix for resource name on SAN |
| ZONE.storage.sanhost | Hostname for SAN device. |
| ZONE.storage.sanpassword | Password for SAN device. |
| ZONE.storage.sanuser | Username for SAN device. |
| ZONE.storage.scpaths | iSCSI Paths for SC. Default value is ’nopath' |
| ZONE.storage.shouldtransfersnapshots | Enable snapshot transfer to the OSG. Setting it to false will disable storing snapshots (full or delta) in object storage. While a false setting will reduce object storage requirements, it also prevents the ability to use a snapshot from one availability zone to create a volume in another zone. You can still take/use snapshots even when the setting is false, but you can only use a snapshot to create a volume in the same zone. Must be set to true to use snapshot deltas, which are managed by the ZONE.storage.maxsnapshotdeltas property.Default: true |
| ZONE.storage.snapexpiration | Time interval in minutes after which Storage Controller metadata for snapshots that have been physically removed from the block storage backend will be deleted |
| ZONE.storage.snapshotpartsizeinmb | Snapshot part size in MB for snapshot transfers using multipart upload. Minimum part size is 5MB |
| ZONE.storage.snapshottransfertimeoutinhours | Snapshot upload wait time in hours after which the upload will be cancelled |
| ZONE.storage.storeprefix | Prefix for ISCSI device |
| ZONE.storage.tid | Next Target ID for ISCSI device |
| ZONE.storage.timeoutinmillis | Timeout value in milli seconds for storage operations |
| ZONE.storage.volexpiration | Time interval in minutes after which Storage Controller metadata for volumes that have been physically removed from the block storage backend will be deleted |
| ZONE.storage.volumesdir | Storage volumes directory. |
| ZONE.storage.writebuffersizeinmb | Buffer size in MB for writing data to snapshot when downloading snapshot from object storage gateway |
| ZONE.storage.zerofillvolumes | Should volumes be zero filled. |
This section covers advanced storage provider configuration options.
The following properties are for tuning the behavior of the Object Storage service and Gateways; the defaults are reasonable and changing is not necessary, but they are available for unexpected situations.